

Currently, ChatGPT and other large language models have become extremely popular, greatly assisting us in synthesis, information retrieval,....
However, these models only know about information that has been pre-trained. This means they lack knowledge of our own data and awareness of reliable information sources.
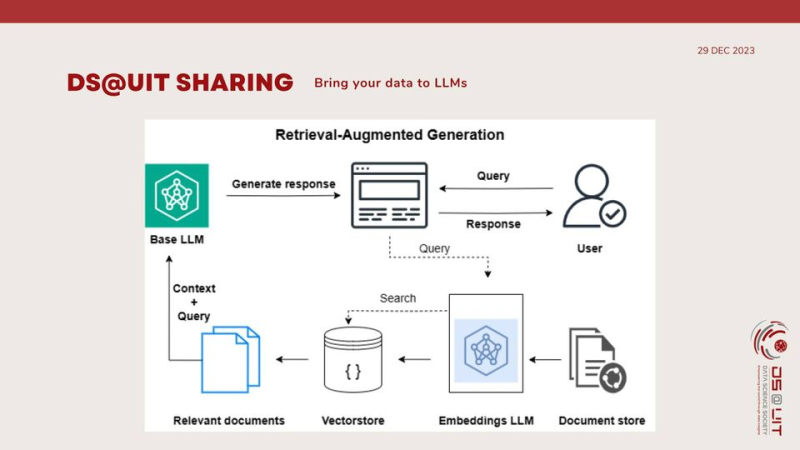
To enhance the ability to answer questions based on provided information, we can incorporate that information from a search step. This helps them provide more accurate answers without the need to retrain these large models. This is the idea behind Retrieval-Augmented Generation (RAG).
There are many tools and techniques available for this purpose, and in this post, we will introduce a method of utilizing the knowledge of ChatGPT on a specific dataset using technical tools such as LangChain and LlamaIndex.
Introduction to LangChain:
LangChain is a framework for developing applications using language models. It enables applications to:
Recognize data: Connect language models to various data sources.
Interact: Allow language models to interact with their environment.
Introduction to LlamaIndex:
LlamaIndex is a tool that simplifies the integration of large language models (LLM) into applications. It facilitates the combination of data from various sources and easy interaction through natural language. It provides a comprehensive and flexible toolkit for building complex applications without the need to retrain the model.
For more details, please visit: https://www.facebook.com/dsociety.uit.ise/posts/pfbid0U9sb8eQ65eRt1ybZmZqXcs23b9RiWEPUfZbNHmQiVr555yqLw6NMKrC4nXd7yd1Bl
Ha Bang - Collaborator in Communication for the University of Information Technology
Translated by Ngoc Diem





