

Many applications in natural language processing rely on adapting one large-scale, pre-trained language model to multiple downstream applications. The major downside of fine-tuning is that the new model contains as many parameters as in the original model. So if the pre-trained model is large (exp. 175 Billion parameters), storing and deploying the fine-tuned models can be challenging.
One of the solution for this is LORA (Low-Rank Adaptation) a technique that accelerates the fine-tuning of large models while consuming less memory.
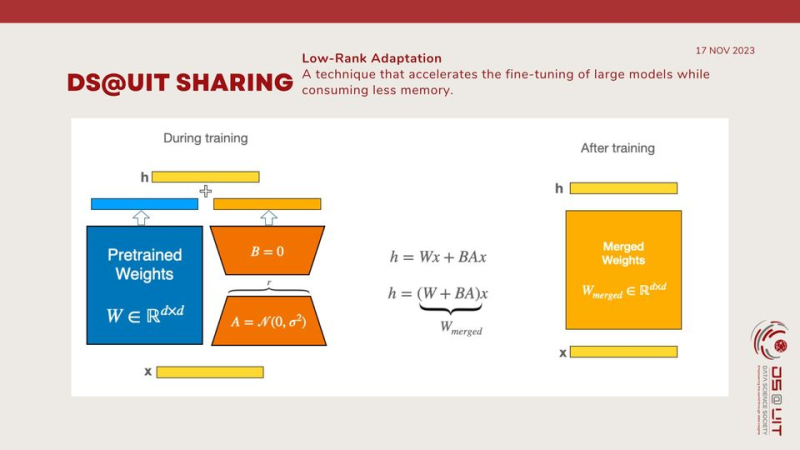
To make fine-tuning more efficient, LoRA’s approach is to represent the weight updates with two smaller matrices (called update matrices) through low-rank decomposition. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
This approach some key advantages:
LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
Performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
LoRA does not add any inference latency because adapter weights can be merged with the base model.
The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
For more details, visit: https://www.facebook.com/dsociety.uit.ise/posts/pfbid0TUKH4aeEg2P...
Ha Bang - Media Collaborator, University of Information Technology
Nhat Hien - Translation Collaborator, University of Information Technology





