

Data labeling is the process of marking or assigning labels to data during machine learning model training. This process helps the model understand and learn from the data, recognizing important patterns and characteristics. Labeling data is a crucial step for the model to learn from experience and make predictions or classifications after being trained.
The labeling process is often done manually or through automated methods, and the quality of labeled data directly impacts the machine learning model's capabilities.
The role of data labeling in machine learning is essential and diverse. Below are some key roles of the data labeling process:
Supervised Learning
Model Guidance: Labeled data helps the machine learning model understand the relationship between input and output. Each data sample is associated with a label, forming the basis for the learning process.
Problem Definition
Setting Goals: Labeling helps clearly define the goal of the machine learning problem. It informs the model about what it needs to predict or classify during training.
Understanding Data Representation
Feature Analysis: Labeling supports the model in understanding the important features of the data. This helps the model identify patterns and significant relationships to make predictions.
Quality Control
Ensuring Accuracy: Correct and accurate data labeling is crucial to avoid errors and ensure the quality of the machine learning model.
Learning Model Generalization
Pattern Learning: Labeled data helps the model learn from known samples and generalize to apply to new, unseen data.
Performance Evaluation
Comparing Predictions with Reality: Labeled data is used to evaluate the performance of the model by comparing predicted outputs with actual labels.
Data Splitting:
Creating Training and Testing Sets: Labeling supports the process of dividing data into training and testing sets to ensure the model is evaluated on data not used during training.
Focus on Specialized Tasks
Deep Labeling: In fields such as healthcare or autonomous vehicles, labeling data may require specialized knowledge to ensure accuracy and safety.
Active Learning
Utilizing Important Data: Active learning techniques can use information from the labeling process to select the most important samples for labeling, optimizing the model's learning.
In summary, data labeling plays a fundamental role in supervised machine learning by providing essential information for training, evaluating, and fine-tuning models. The quality and relevance of labeled data directly influence the performance and generalization ability of machine learning models.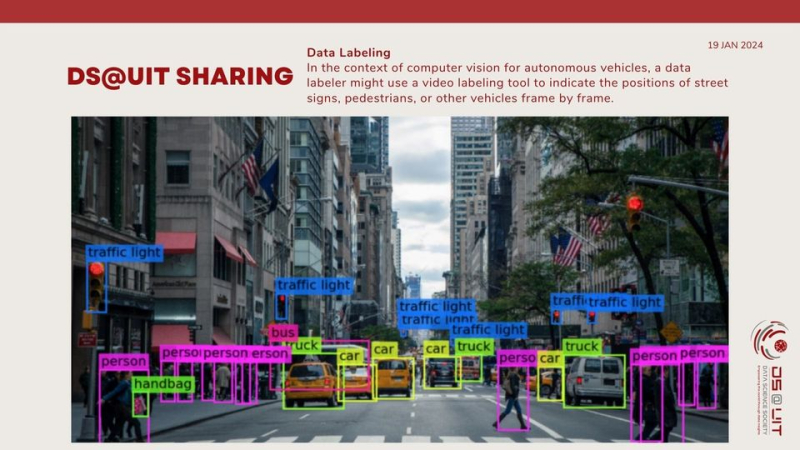
Detailed Information: https://www.facebook.com/dsociety.uit.ise/posts/pfbid0xKCjpouasVkikNT13tPmNTMZ13QX7GGi41roBpqciGN8cwwdUNogLwcvCNoTj1SWl
Hạ Băng - Communication Collaborator, University of Information Technology
English version: Phan Huy Hoang






{kind=link}